
環境
Windows 11 64bit
Visual Studio 2022
在 C++ 的學習過程中,讀取 txt 文字檔是基本操作,但是….身為台灣人,應該很常遇到這問題。
首先,右鍵新增一個 txt 文件
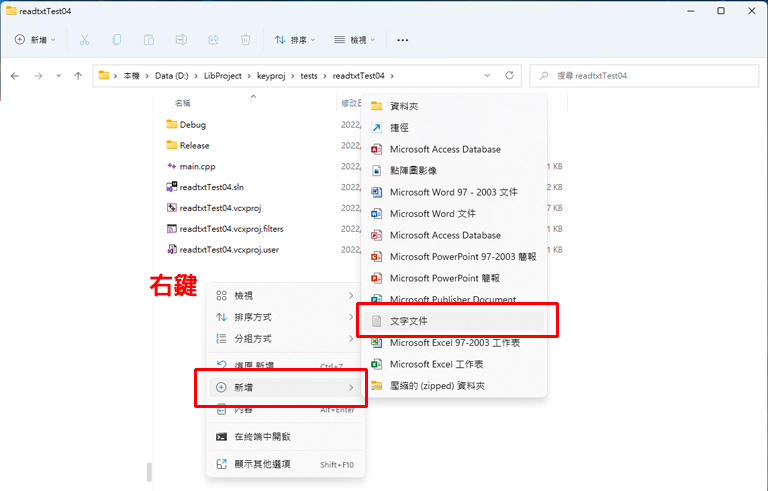
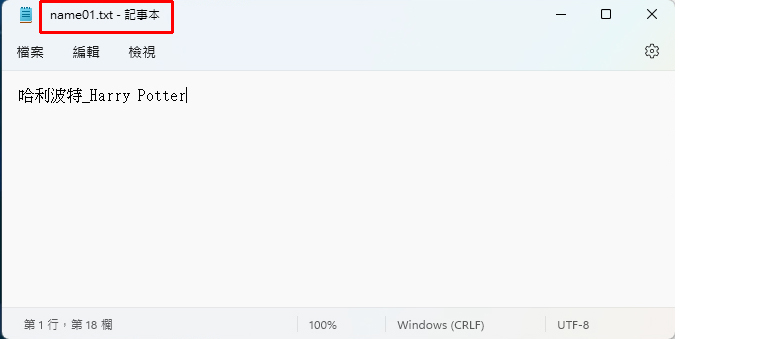
先取名 name01.txt,輸入以下內容,就是有中文有英文就好
| 哈利波特_Harry Potter |
用 C++ 讀檔
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
ifstream ifs;
char szBuffer[256] = "";
ifs.open("name01.txt");
if (!ifs.is_open())
{
cout << "Failed to open file." << endl;
}
else
{
ifs.read(szBuffer, sizeof(szBuffer));
ifs.close();
cout << szBuffer << endl;
}
system("pause");
return 0;
}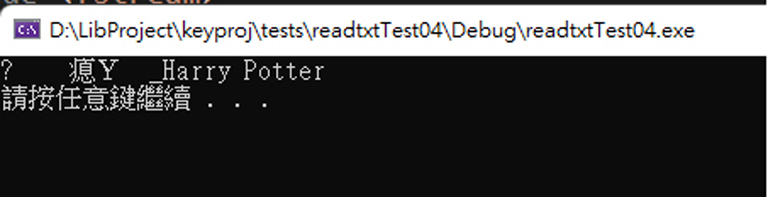
嗯….中文部分亂碼
改用 C 的 fopen 試試看呢?
#include <iostream>
using namespace std;
int main()
{
FILE* fp = NULL;
char szBuffer[256] = "";
fopen_s(&fp, "name01.txt", "r");
if (fp == NULL)
{
printf("Failed to open file.\n");
}
else
{
fread(szBuffer, sizeof(char), sizeof(szBuffer), fp);
fclose(fp);
printf("%s\n", szBuffer);
}
system("pause");
return 0;
}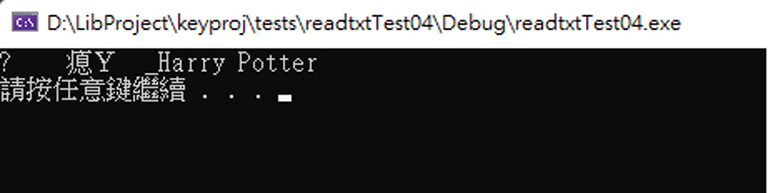
嗯….還是亂碼
雖然呢,把 txt 裡的中文拿掉就好,但是一定會遇到要處理中文字的狀況,所以這裡還是不能偷懶。
那為什麼會有這亂碼問題呢?原因如下:
1. 這個 txt 檔的編碼方式是 utf8。windows 以前 txt 檔的預設編碼是 ansi,windows 10 之後預設編碼變成了 utf8。
2. C++ 裡可以處理的字串編碼只有 ansi 和 unicode,沒有 utf8。
3. console 的命令提示字元視窗,預設顯示的編碼是 ansi。
3 個階段的編碼方式都不同,當然會是亂碼。
因此我的處理方式會是
1. txt 還是 utf8
2. C++ 裡用 unicode
3. 讓 console 的命令提示字元視窗顯示 unicode
簡單來說就是用程式全部轉成 unicode 來處理就對了。
首先,因為 C++ 讀檔進來的字串編碼是 utf8,所以要把 utf8 轉換成 unicode,再把命令提示字元視窗改成可顯示 unicode 就可以了。
#include <iostream>
#include <fstream>
#include <windows.h>
#include <tchar.h>
using namespace std;
void UTF8ToUnicode(wchar_t* szUni, const char* szUtf) //把 UTF8 轉成 Unicode
{
MultiByteToWideChar(CP_UTF8, 0, szUtf, -1, szUni, (int)strlen(szUtf) * 2);
}
void PrintfUnicode(const wchar_t* szFormat, ...) //在 console 印出 Unicode
{
const int MAX_PRINT_NUM = 1024;
wchar_t szPrint[MAX_PRINT_NUM] = L"";
va_list pArgs;
va_start(pArgs, szFormat);
vswprintf_s(szPrint, szFormat, pArgs);
va_end(pArgs);
WriteConsoleW(GetStdHandle(STD_OUTPUT_HANDLE), szPrint, (DWORD)wcslen(szPrint), NULL, NULL);
}
int main()
{
ifstream ifs;
char szUtf8[256] = "";
ifs.open("name01.txt");
if (!ifs.is_open())
{
cout << "Failed to open file." << endl;
system("pause");
return 0;
}
ifs.read(szUtf8, sizeof(szUtf8));
ifs.close();
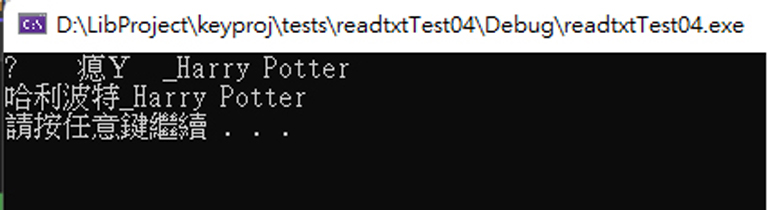
cout << szUtf8 << endl;
wchar_t szUnicode[512] = L"";
UTF8ToUnicode(szUnicode, szUtf8); //把 UTF8 轉成 Unicode
PrintfUnicode(L"%s\n", szUnicode); //在 console 印出 Unicode
system("pause");
return 0;
}
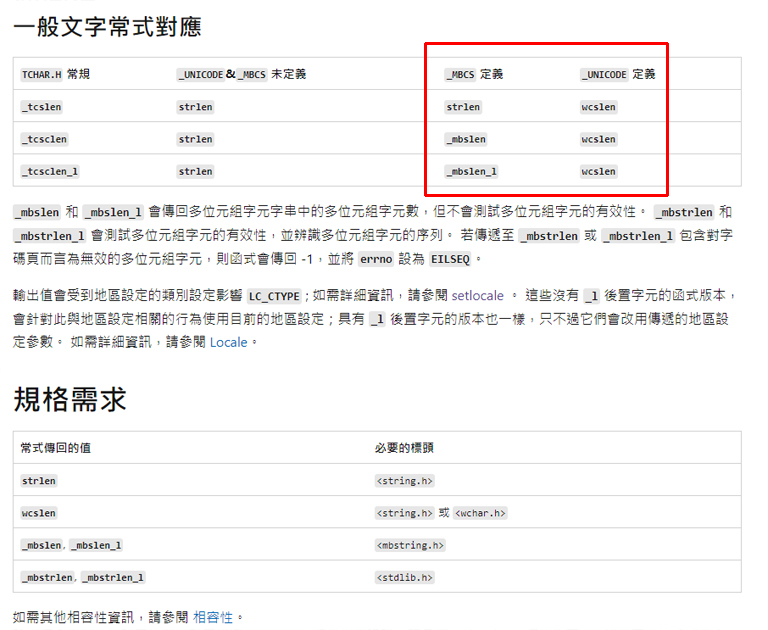
在 C++ 中轉成 unicode 之後,就可以使用各種字串處理函式,比方說計算字串長度的 strlen,在 unicode 的版本是 wcslen,以下列出一些:
| ansi(MBCS) | unicode | |
| 字元資料型態 | char | wchar_t |
| 字元 | char sz=’a’; | wchar_t sz=L’a’; |
| 字串 | char sz[]=”abc”; | wchar_t sz[]=L”abc”; |
| C++字串資料型態 | std::string | std::wstring |
| 計算字串長度 | strlen | wcslen |
| 字串複製 | strcpy | wcscpy |
類似這樣的字串處理函式的對應可以在 Microsoft 的 MSDN 中查詢。
至於這些編碼之間的關係,簡單整理如下:(其實編碼方式不只這些,如果想知道詳細,網路上有很多文章介紹)

你可能會想,一定要把 utf8 改成 unicode 再用 wcsXXX系列嗎?不能把 utf8 改成 ansi 然後用 strXXX 系列嗎?
也是可以啊,我也知道 strXXX 系列比較習慣,而且外國人都用這個啊!那當然,這些英文國家的人根本就不在乎什麼 unicode 的問題好嗎(怒)!如果你確定自己處理的資料不會遇到英文以外的語言,就可以這麼做。
或許也會有人會覺得,改掉 txt 檔和 console 的預設編碼不就好了嗎?網路上也有很多文章這樣教啊?
我是不建議使用更改預設值的方式。因為你寫出來的程式是會在別的國家的人的電腦中執行,你根本沒有辦法去更改別人電腦的預設值啊!所以讓自己的程式能夠應付各種語言狀況才是比較好的方法。
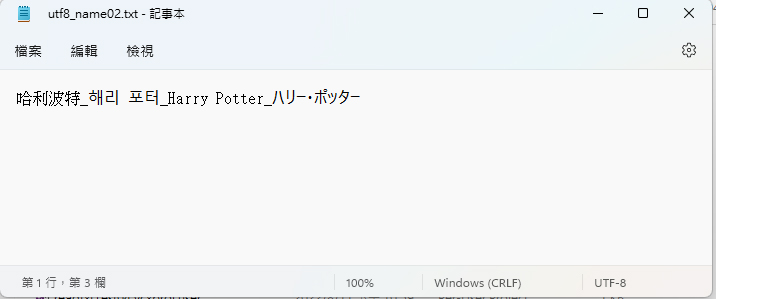
既然知道了是編碼問題,來試試下面的 txt 檔。有中文、日文、韓文、英文,然後切 token 看看。
| 哈利波特_해리 포터_Harry Potter_ハリー・ポッター |
#include <iostream>
#include <fstream>
#include <windows.h>
#include <tchar.h>
using namespace std;
void UTF8ToUnicode(wchar_t* szUni, const char* szUtf) //把 UTF8 轉成 Unicode
{
MultiByteToWideChar(CP_UTF8, 0, szUtf, -1, szUni, (int)strlen(szUtf) * 2);
}
void PrintfUnicode(const wchar_t* szFormat, ...) //在 console 印出 Unicode
{
const int MAX_PRINT_NUM = 1024;
wchar_t szPrint[MAX_PRINT_NUM] = L"";
va_list pArgs;
va_start(pArgs, szFormat);
vswprintf_s(szPrint, szFormat, pArgs);
va_end(pArgs);
WriteConsoleW(GetStdHandle(STD_OUTPUT_HANDLE), szPrint, (DWORD)wcslen(szPrint), NULL, NULL);
}
int main()
{
ifstream ifs;
char szUtf8[256] = "";
ifs.open("utf8_name02.txt");
if (!ifs.is_open())
{
cout << "Failed to open file." << endl;
system("pause");
return 0;
}
ifs.read(szUtf8, sizeof(szUtf8));
ifs.close();
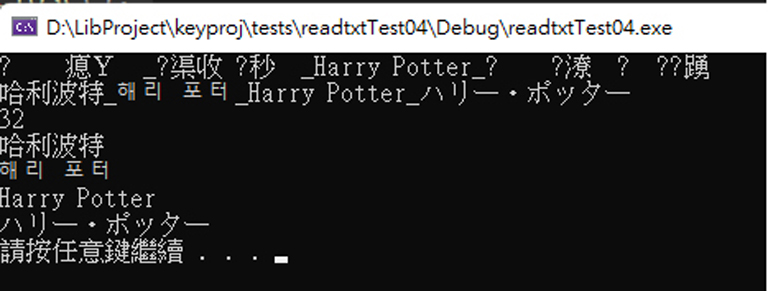
cout << szUtf8 << endl;
wchar_t szUnicode[512] = L"";
UTF8ToUnicode(szUnicode, szUtf8); //把 UTF8 轉成 Unicode
PrintfUnicode(L"%s\n", szUnicode); //在 console 印出 Unicode
cout << wcslen(szUnicode) << endl; //Unicode 字串長度
//
wchar_t* w = NULL;
wchar_t* temp = NULL;
w = _wcstok_s_l(szUnicode, L"_", &temp, LC_ALL);
while (w != NULL)
{
PrintfUnicode(L"%s\n", w);
w = _wcstok_s_l(NULL, L"_", &temp, LC_ALL);
}
system("pause");
return 0;
}
下一篇:C++ -讀取 txt 文字檔
https://husking-studio.com/cpp-txt-file-02/